Monday, December 10, 2018
Thursday, June 14, 2018
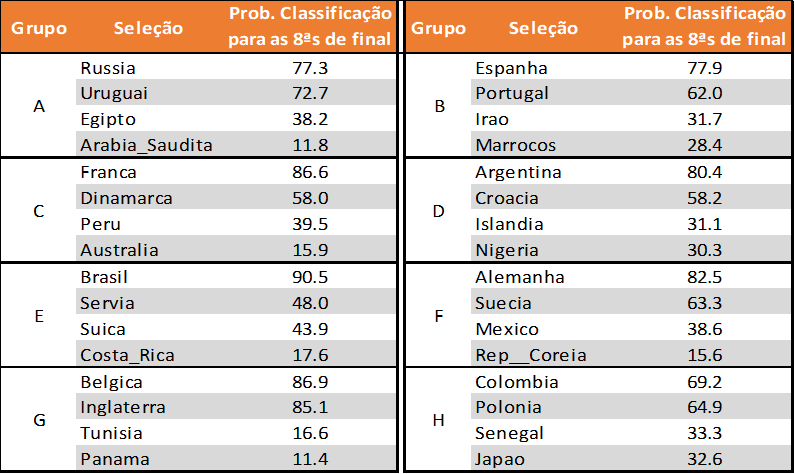
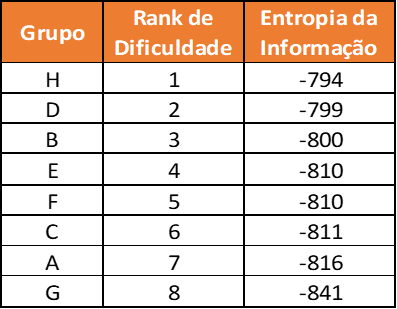
Qual grupo da Copa do Mundo de 2018 é mais difícil?
Wednesday, February 15, 2017
Banco de dados sobre terrorismo
Após a posse do novo presidente americano Donald Trump em 20/01/2017, diversas ações do americano têm causada bastante polêmica. Talvez a medida mais polêmica de todas tenha sido a proibição da entrada nos EUA de qualquer pessoa dos seguintes países: Síria, Iraque, Irã, Líbia, Sudão, Iêmen e Somália. Detalhes sobre essa medida podem ser encontrados nesse artigo.
O que causou mais controvérsia, além do fato dessa ser uma medida extremamente arbitrária, tratando todos os cidadãos desses países como terroristas, foi a aparente falta de critério claro na escolha dos 7 países. Como pode ser visto aqui, não há registro de nenhum terrorista desses países atuando em território americano desde o ataque de 11 de setembro.
Com todas essas notícias sobre essa medida, pensei que seria interessante calcular qual é a chance de uma pessoa ser terrorista dado que ela é de um desses países. Dessa forma podemos quantificar de forma precisa o risco que se corre ao deixar cidadãos desses países entrarem em seu território. Também poderia avaliar em quais países essa chance é maior. Ou seja, poderíamos avaliar se têm sentido as escolhas feitas por Trump.
Para fazer essas contas, precisamos apenas do Teorema de Bayes e da nacionalidade dos terroristas, além do tamanho populacional dos países envolvidos. Pra minha tristeza, não consegui encontrar a nacionalidade dos terroristas.
Por outro lado, encontrei uma grande quantidade de informações em bases de dados sobre terrorismo, como pode ser visto nesse site, na seção "Data Sources". A análise que eu queria fazer não é possível ainda, mas muitas outras podem ser realizadas com esses dados, por isso resolvi ajudar na divulgação dos mesmos para que o assunto possa ser melhor estudado.
Mas ainda tenho esperança que informações sobre a nacionalidade dos terroristas sejam coletadas, pois ajudariam muito na discussão dessa medida polêmica adotada pelo Trump.
Tuesday, January 31, 2017
É "justo" que a premiação do tênis para torneios masculinos e femininos seja igual?
Distância
|
Homem
|
Mulher
|
Diferença
%
|
100 m
|
0'9''58
|
0'10''49
|
9.5%
|
200 m
|
0'19''19
|
0'21''34
|
11.2%
|
400 m
|
0'43''03
|
0'47''6
|
9.4%
|
800 m
|
1'40''9
|
1'53''3
|
12.9%
|
1 km
|
2'12''0
|
2'29''0
|
12.9%
|
1,5 km
|
3'26''0
|
3'50''1
|
11.7%
|
2 km
|
4'44''8
|
5'25''4
|
14.4%
|
3 km
|
7'20''7
|
8'06''1
|
10.4%
|
5 km
|
12'37''4
|
14'11''2
|
12.4%
|
10 km
|
26'17''5
|
29'17''4
|
11.4%
|
20 km
|
55'21''0
|
60'01''54
|
8.4%
|
Meia Maratona (21 km)
|
58'23''0
|
60'05''09
|
2.9%
|
Maratona (42 km)
|
120'02''57
|
120'17''42
|
0.2%
|
100 km
|
360'13''33
|
360'33''11
|
0.1%
|
Cenário 1
|
Cenário 2
|
|
Sets Disputados Mulheres
|
3
|
5
|
Sets Disputados Homens
|
5
|
5
|
Esforço realizado (# sets
Mulheres/Homens)
|
60%
|
100%
|
Esforço "ideal"
|
88%
|
88%
|
Diferença
|
-28%
|
12%
|
Thursday, December 8, 2016
Na Copa do Brasil, é mais vantajoso jogar o primeiro ou o segundo jogo em casa?


Para finalizar, me parece interessante apresentar uma tabela (acima) com as chances de vitória do time que joga o primeiro jogo em casa dependendo do número de gols marcados no primeiro jogo (tanto pelo time de casa quanto o visitante). Nessa tabela estamos considerando apenas as fases finais do campeonato. Se de fato na final os times visitantes no primeiro jogo tendem a ser mais conservadores, e não fazerem gols, vemos que a probabilidade de vitória para os mandantes do primeiro jogo, quando não sofrem gols, é de 54%.